自动驾驶和自然语言如何结合?NuPrompt来了!
原标题:Language Prompt for Autonomous Driving
论文链接:https://arxiv.org/pdf/2309.04379.pdf
作者单位:北京理工大学 澳门大学 MEGVII Technology 北京人工智能研究院
代码链接:https://Github.com/wudongming97/Prompt4Drivinguunw

论文思路
计算机视觉领域的一个新趋势是根据自然语言提示符表示的灵活的人类命令捕获感兴趣的目标。然而,由于缺乏配对提示实例(prompt-instance)数据,在驾驶场景中使用语言提示的进展陷入了瓶颈。为了解决这个问题,本文提出了第一个以目标为中心的语言提示集,用于3D、多视图和多帧空间中的驾驶场景,名为NuPrompt。它扩展了Nuscenes的数据集,构造了总共35367个语言描述,每个描述平均引用5.3个目标轨迹。基于新基准中的目标-文本对(object-text pAIrs),本文制定了一个新的基于提示的驾驶任务,即使用语言提示来预测所描述的目标的跨视图和帧的轨迹(trajectory)。此外,本文还提供了一个简单的基于Transformer的端到端基线模型,名为PromptTrack。实验表明,本文的PromptTrack在NuPrompt上取得了令人印象深刻的性能。本文希望这项工作能为自动驾驶社区提供更多新的见解。
主要贡献
本文提出了一种新的大规模语言提示集(language prompt set),名为NuPrompt。据本文所知,它是第一个专门研究视频领域多个感兴趣的3D目标的数据集。
本文构造了一个新的基于提示的驾驶感知任务,要求使用语言提示作为语义线索来预测目标的轨迹。
本文开发了一个简单的端到端基线模型,称为PromptTrack,它有效地融合了新构建的提示推理分支中的跨模态特征,以预测参考目标(referent objects),显示了令人印象深刻的性能。
网络设计
为了推进驾驶场景中提示学习的研究,本文提出了一种新的大规模基准,名为NuPrompt。基准测试是建立在流行的多视图3D目标检测数据集Nuscenes[2]上的。本文将语言提示分配给具有相同特征的目标集合,以便为它们奠定基础(for grounding them)。从本质上讲,这个基准提供了许多3D实例-文本匹配,具有三个主要属性:
1.真实驾驶描述。
与现有的基准测试只表示来自模块化图像的2D目标不同,本文数据集的提示描述了来自3D、环顾四周和长时间空间的各种与驾驶相关的目标。图1展示了一个典型的例子,即一辆车在多个视图中从后面到前面超过了我们的车。
2.实例级提示标注。
每个提示符都表示一个细粒度的、有区别的、以目标为中心的描述,并允许它覆盖任意数量的驱动目标。
3.大规模语言提示。
就提示符的数量而言,NuPrompt可以与当前最大的数据集[7]相媲美,即包含35367个语言提示符。
与基准一起,本文制定了一个新的基于提示的感知任务,其主要目标是使用给定的语言提示来预测和跟踪驾驶环境中的多个 3D目标。该任务的难点在于两个方面:跨帧时间关联和跨模态语义理解。为了解决这一挑战,本文提出了一种端到端的基线,它建立在camera-only 3D tracker PF-Track[24]上,命名为PromptTrack。请注意,PF-Track通过它的过去和未来推理分支展示了出色的时空建模。此外,本文增加了一个快速推理分支来进行跨模态的融合和理解。具体来说,本文的提示推理涉及到提示嵌入和查询特征之间的交叉注意力,这些特征来自过去的推理,进一步预测 prompt-referred 目标。
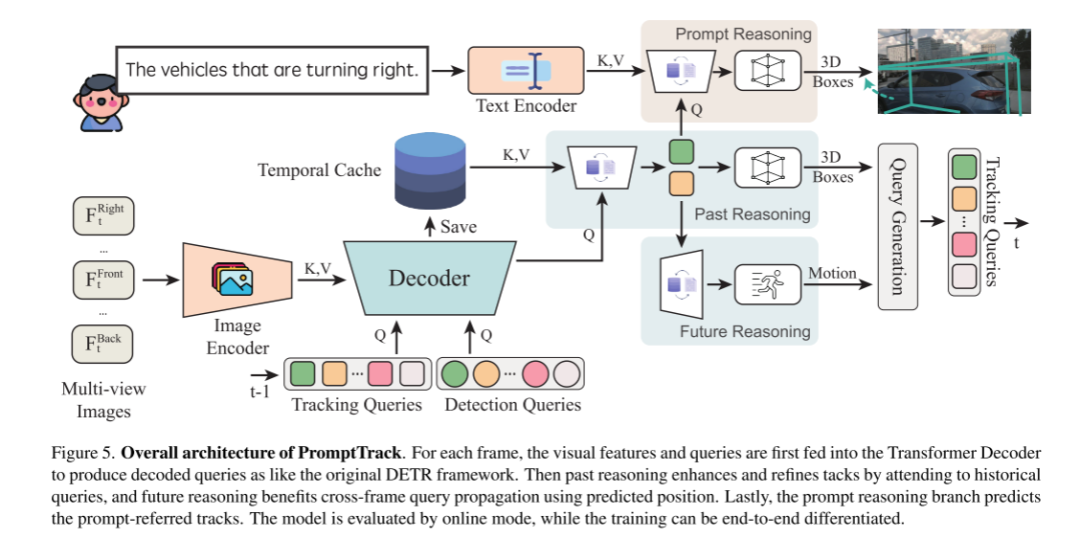
图5。PromptTrack的总体架构。对于每一帧,视觉特征和查询首先被输入到Transformer解码器中,以产生类似于原始DETR框架的解码查询。然后,过去的推理通过处理历史查询来增强和改进策略,而未来的推理则有利于使用预测位置进行跨帧查询传播。最后,快速推理分支预测 prompt-referred 轨迹。该模型采用在线模式进行评价,训练可进行端到端 differentiated。

图2。语言提示标注过程Pipeline,包括三个步骤:语言元素收集、语言元素组合、描述生成。首先,在语言元素收集阶段,本文将每个语言标签与 referent objects 配对。然后,在语言元素组合阶段,选择并组合某些语言元素。最后,根据得到的组合,在描述生成阶段采用大型语言模型(LLM)创建语言描述。

图1。一个来自NuPrompt的典型例子。语言提示“正在超车的车辆”,在三维、多帧、多视图空间内精确注释并匹配驾驶目标。NuPrompt包含35367个目标-提示符对。

图3。NuPrompt的前100个单词的词云。它有大量的词来描述驾驶物体的外观,如“黑”、“白”、“红”等,并涵盖了许多运动场景,如“走”、“动”、“过”等。
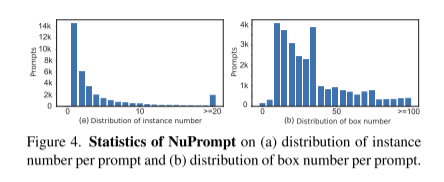
图4。NuPrompt的统计信息:(a)每个提示符的实例数分布和(b)每个提示符的框数分布。
实验结果




引用
Wu, D., Han, W., Wang, T., Liu, Y., Zhang, X., & Shen, J. (2023). Language Prompt for Autonomous Driving. ArXiv. /abs/2309.04379















