年薪50万都难招的大数据工程师,凭什么?
回顾2018年,降薪、裁员、互联网寒冬似乎成为主旋律,那实际上资本市场萎缩了吗?
其实不然,2018年6月,蚂蚁金服还获得140亿融资,而热度较高的大数据行业,在2018年的融资额达到1273.1亿元,是2017年的2倍。所以对于市场来说好的项目、好的行业永远值得被投资。
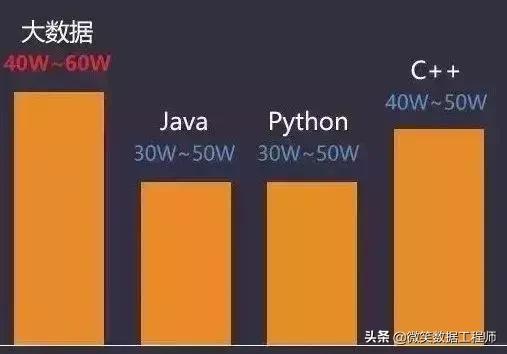
目前,一个大数据工程师月薪轻松过万,一个有几年工作经验的数据分析师,薪酬在40万~60万元之间,而更顶尖的大数据技术人才则是年薪轻松超百万,就连大数据开发应届生的也早已轻松领20万年薪。
01
五位一线大咖坐镇
02
课程历经四次迭代,技术时刻保持最新
03
全程直播,实时解决问题不留疑点
04
随堂作业,助教跟班,保证教学质量
05
五大实战项目,对接企业需求
课程简介
■15个重点模块,212个知识点
相较于前几期课程,本期课程在细节技术材料及课件上做了更新外,本次新增了《spark ML算法》模块巩固底层知识,以及《JAVA性能优化和分布式中间件》模块有针对性的拔高。
2019大数据实战大纲(全栈型)
一.linux 操作系统
在企业中无一例外的是使用 Linux 来搭建或部署项目,在平常我们也经常在Linux环境下进行开发。进入大数据领域就要打好 Linux 基础,以便更好地学习Hadoop,Kafka,Spark,Storm,redis 等众多课程。
1.Linux来源与发展状况
2.Linux常见发行版
3.Linux安装
4.Linux版本信息
5.Linux基础操作命令
6.Linux目录结构介绍
7.Linux系统用户账号管理
8.Linux系统用户组管理
9.Linux系统用户相关文件讲解
10.Linux sudo权限说明
11.Linux常用文件命令
12.Linux常用目录命令
13.Linux文件信息查看
14.Linux文件与目录统计技巧
15.Linux文件属性
16.Linux文件类型
17.Linux文件与目录查找技巧
18.Linux文本文件操作
19.Linux文件权限,压缩与解压缩
20.Linux系统运行与进程运行信息
21.Linux查看磁盘空间
22.Linux环境变量
23.Linux Shell编程
24.Linux进程的查看与终结
25.Linux输入输出与重定向
26.Linux远程登录与重定向
实战项目:编写一个每天清理个人目录下.log后缀文件的脚本,清理到自定义回收站,每天两点执行。
二.Hadoop生态圈(离线计算)
Hadoop是一种分析和处理大数据的软件平台,是Appach的一个用Java语言所实现的开源软件的加框,在大量计算机组成的集群当中实现了对于海量的数据进行的分布式计算。在本章节中不仅将用到前面的 Linux 知识,而且会对 hadoop 的架构有深入的理解,并未你以后架构大数据项目打下坚实基础
Hadoop
1.hadoop 介绍,发展简史,诞生来由
2.hadoop 生态圈体系结构,组件说明
3.hadoop 伪分布式环境搭建及完全分布式环境说明
4.Hadoop安全认证方面的讲解
5.Hadoop集群如何扩容
HDFS
1.HDFS分布式文件系统说明
2.HDFS block概念
3.HDFS namenode ,datanode 详解
4.HDFS HA 详解
5.HDFS命令行接口,读取数据
6.HDFS命令行接口,写⼊数据
7.HDFS命令行接口,删除数据
8.HDFS命令行接口,distcp跨集群分布式拷⻉数据
9.HDFS压缩和分片
10.HDFS文件格式:textfile,sequencefile,rcfile,orcfile,parquet
11.HDFS各类文件格式比较
YARN
1.经典的Mapreduce 1结构弊端
2.Mapreduce 2 中YARN的引入
3.YARN的核心结构说明
4.YARN的⼯作机制
5.YARN的架构剖析
6.YARN 内置调度器:公平调度和容量调度
7.YARN上任务的执行环境
8.YARN上任务的推测执行机制
9.YARN上任务的JVM重用
Mapreduce
1.MapReduce整体流程说明
2.MapReduce目录输入,多目录输入,inputformat子类介绍
3.Mapreduce map 过程
4.Mapreduce combine过程
5.Mapreduce reduce 过程
6.Mapreduce结果输出,outputformat子类介绍
7.MapReduce世界的helloword之wordcount操作演练
8.MapReduce Wordcount 项⽬打包,运⾏
9.MapReduce 内置计数器含义讲解
10.Mapreduce 实例讲解之全排序
11.Mapreduce 实例讲解之部分排序
12.Mapreduce 实例讲解之 join map端连接
13.Mapreduce 实例讲解之 join reduce端连接
14.Mapreduce 实例讲解之矩阵相乘
15.Mapreduce自定义的format
16.Mapreduce MRUnit单元测试使用
Hadoop Streaming
1.hadoop streaming引入的目的
2.Hadoop streaming机制讲解
3.使用Python编写 hadoop streaming
4.使用Shell 编写 hadoop streaming
实战项目: 分别使用原生mr和python版本的hadoop streaming,编写数据清洗,数据处理,压缩逻辑,结果dump到hdfs。
三.Hive(数据仓库)
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析 。Hive是工作中最常用到的部分,也是面试的重点。
1.Hive 简介
2.Hive Hbase Pig三者的不同点
3.Hive 系统架构
4.Hive 安装搭建与常用参数配置
5.Hive shell命令使用
6.Hive 数据库数据表操作
7.Hive 数据导出
8.Hive 数据加载
9.Hive 外部表与分区表讲解
10.HiveQL 常⽤语句
11.HiveServer2讲解
12.Hive 函数介绍
13.Hive 分析函数与窗口函数
14.Hive ⾃定义UDF / UDAF函数
15.Hive 优化和安全
实战项目:结合flume等框架的日志处理
四.Sqoop(数据迁移工具)
sqoop 主要用于在Hadoop(Hive)与传统的数据库(MySQL、postgresql...)间进行数据的传递,可以将一个关系型数据库中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
1.Sqoop框架介绍
2.Sqoop框架原理分析
3.Sqoop框架安装步骤演示
4.Sqoop1和Sqoop2分析对比
5.Sqoop深入了解数据库导入原理
6.Sqoop导出数据原理分析
7.Sqoop 设置存储格式与使⽤压缩
8.Sqoop导入数据到hdfs分析实战
9.Sqoop 增量导⼊功能代码实现
10.Sqoop RDBMS与Hive的操作演示
备注:sqoop主要是源码分析和API使用,考虑到中小型公司使用频次,将会在项目中演示用法。
五.HBase(分布式数据库)
HBase是一个开源的非关系型分布式数据库(NoSQL),它参考了谷歌的BigTable建模,实现的编程语言为 Java。HBase在列上实现了BigTable论文提到的压缩算法、内存操作和布隆过滤器。HBase的表能够作为MapReduce任务的输入和输出,可以通过Java API来访问数据。也可以通过REST、Avro或者Thrift的API来访问。
虽然最近性能有了显著的提升,HBase 还不能直接取代SQL数据库。如今,它已经应用于多个数据驱动型网站,包括 Facebook的消息平台
1.HBase 综合概述
2.HBase 数据库特点
3.HBase 搭建
4.HBase Shell 操作讲解
5.HBase Java API 讲解
6.HBase 协处理器使用
7.HBase 与Mapreduce集成使用讲解
8.HBase backup master讲解
9.HBase 数据模型讲解
10.HBase 数据库数据存储与读取思想讲解
11.HBase 数据在线备份思路讲解
12.HBase 数据迁移与导入方案讲解
13.Region 寻址⽅式
14.HBase 二级索引构建方案
15.HBase RowKey设计原则
16.HBase 性能调优
六.Flume(分布式日志收集系统)
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
1.Flume框架原理和应用场景分析
2.Flume框架使用场景分析
3.Flume概述以及原理解析
4.Flume中Event的概念和Socket的关联
5.Flume运行机制分析
6.NetCat Source源码分析
7.Flume agent原理说明和shell配置
实战项目:Flume和HDFS的结合使用,在HDFS中采集数据,收集Hive运行的目录到hdfs文件系统。
七、Scala 课程
Scala是一门多范式的编程语言,一种类似java的编程语言 ,设计初衷是实现可伸缩的语言 、并集成面向对象编程和函数式编程的各种特性。
1.scala 环境配置
2.scala 体系结构
3.scala 解释器、变量、常用数据类型等
4.scala 的条件表达式、输入输出、循环等控制结构
5.scala 的函数、默认参数、变长参数等
6.scala 的数组、变长数组、多维数组等
7.scala 的映射、元组等操作
8.scala 的类,包括 bean 属性、辅助构造器、主构造器等
9.scala 的对象、单例对象、伴生对象、扩展类、apply 方法等
10.scala 的包、引入、继承等概念
11.scala 的特质
12.scala 的操作符
13.scala异常处理
八.Kafka(流处理平台)
Kafka 是在大数据流处理场景中经常使用的分布式消息系统,配合 Spark 内存计算框架, 是流处理场景中的黄金组合。本课程以实战的方式学习 Kafka 分布式消息系统,包括 Kafka 的安装配置、Producer API 的使用、Consumer API 的使用以及与第三方框架(Flume、 Spark Streaming)的集成开发。每个知识点的学习,都有编程实战和操作实战,用眼见为 实的方式学习抽象的理论概念。
1.Kafka 入门
2.Kafka 集群搭建理论与实践
3.Kafka Topic 实战
4.Kafka 开发 Producer 理论与实践
5.Kafka 开发 consumer 理论与实践
6.Kafka 发送和接收结构化数据
7.Kafka 发送和接收非结构化数据
8.Kafka 整合 Flume 框架
9.spark 读取 kafka 数据
九、Spark Core
Spark 内存计算框架,是当前最流行的大数据计算框架,Spark 已经成为大数据开发人员以 及数据科学家的必备工具。
本课程主要学习 Spark Core 的内容。包括 Spark 集群安装、Spark 开发环境搭建,Spark Core 编程模型、Spark 程序运行原理、Spark 性能调优等。
1.Spark 的起源及其哲学思想
2.Spark 集群的安装、启动、测试
3.Spark 基本架构及 API 介绍
4.Spark 开发环境搭建并开发运行 wordCount 程序(Scala、 Java)
5.wordCount 程序的集群部署及 Spark UI 简介
6.Spark 计算框架的核心抽象--RDD(理论及入门)
7.Spark RDD创建实战(Scala、 Java)
8.Spark RDD 操作--transformation 算子实战(Scala、 Java)
9.Spark RDD 操作--action 算子实战(Scala、 Java)
10.Spark RDD计算结果保存实战(Scala、 Java)
11.Spark RDD 缓存及持久化实战(Scala、 Java)
12.Spark 分布式共享变量实战--累加器和广播变量(Scala、 Java)
13.Spark 程序集群部署方式实战
14.Spark 程序运行流程分析
15.Spark 程序的监控和调试
16.Spark 内核解读
17.Spark 性能调优(shuffle)
18.Spark Core 数据分析实战
19. Spark内存管理模型
20. Spark性能调优(shuffle)
21. Spark源码阅读入门
十.Spark SQL
很多初学者,对大数据的概念都是模糊不清的,大数据是什么,能做什么,学的时候,该按照什么线路去学习,学完往哪方面发展,想深入了解,想学习的同学欢迎加入大数据学习扣扣群:740041381,有大量干货(零基础以及进阶的经典实战)分享给大家,并且有清华大学毕业的资深大数据讲师给大家免费授课,给大家分享目前国内最完整的大数据高端实战实用学习流程体系。
本课程将深入浅出学习 Spark 的结构化 API(DataFrame、Dataset 和 SQL)。SparkSQL 是在大数据项目中,Spark 开发工程师经常使用的 Spark 模块,除了深入讲解 SparkSQL 本身的每个知识点、SparkSQL 性能调优,还会涉及到 HDFS、Hive、HBase、MongoDB、 Oracle、MySQL 等第三方数据存储框架。每个知识点都以代码实战的方式讲解,知其然,更知其所以然。
1.Spark SQL 背景介绍
2.SparkSQL、 DataFrame、 Dataset 之间的关系
3.SparkSQL 概述
4.SparkSQL 数据类型
5.SparkSQL join 操作实战
6.SparkSQL 读写数据实战
7.SparkSQL 操作 Hive 中的数据
8.SparkSQL 调优
9.SparkSQL 数据分析案例实战
10. Spark SQL join操作实战及调优
11. SparkSQL UDAF开发实战
12. SparkSQL窗口函数实战
13. SparkSQL数据分析案例1(购物网站数据分析)
14. SparkSQL数据分析案例2(交通车辆—套牌车分析)
十一.Spark Streaming(流处理平台)
Spark streaming是Spark核心API的一个扩展,它对实时流式数据的处理具有可扩展性、高吞吐量、可容错性等特点。我们可以从kafka、flume、Twitter、 ZeroMQ、Kinesis等源获取数据,也可以通过由高阶函数map、reduce、join、window等组成的复杂算法计算出数据。最后,处理后的数据可以推送到文件系统、数据库、实时仪表盘中。事实上,你可以将处理后的数据应用到Spark的机器学习算法、 图处理算法中去。
1.Spark Streaming 框架机制
2.Spark Streaming 时间和窗口的概念
3.Spark Streaming DStream和RDD的关系
4.Spark Streaming 性能调优
5. Spark Streaming整合Kafka的两种方式
6. SparkStreaming整合kafka:如何实现exactly once消费语义
7. Spark Streaming数据分析案例:黑名单过滤
实战项目:读取kafka数据做聚合处理,条件过滤后写入HDFS
十二、Spark ML(机器学习算法)
理论基础:Spark MLlib 概述、数据结构、应用场景Spark实现回归算法、分类算法、算法原理概述等。
1. 推荐系统介绍和系统原理
2. 推荐系统中的个性化推荐 - 召回算法
3. 推荐系统中的个性化推荐 - 排序算法
4. 基于Spark mllib回归算法、分类算法 ,协同过滤算法
5. 大规模机器学习平台(Angle)
十三.Storm (分布式实时数据计算系统)
Storm是一个开源的分布式实时计算系统,可以简单、可靠的处理大量的数据流。而且支持水平扩展,具有高容错性,保证每个消息都会得到处理。Storm处理速度很快(在一个小集群中,每个结点每秒可以处理数以百万计的消息)。
Storm的部署和运维都很便捷,更为重要的是可以使用任意编程语言来开发应用。
1.Storm 简介
2.Storm 原理和概念
3.Storm 与 Hadoop 的对比
4.Storm 环境搭建
5.Storm API 入门
6.Storm Spout
7.Storm Grouping策略及并发度
8.Storm 优化引入zoolkeeper锁控制线程
9.Storm 去重模式
10.Storm shell脚本开发
11.Storm 批处理事务
12.Storm 普通事务分区事务
13.Storm 按天计算
14.Storm 不透明分区事务
15.Storm 事务
16.Storm Trident
十四、Java性能优化和分布式中间件探析
1.再谈JVM 内存模型
2.JVM算法和垃圾回收机制
3.JVM生产环境监控命令和指标
4.JVM面试常考点分析
5.Java多线程实战
6.Java锁机制分析和优化
7.Kafka 和 ZooKeeper 的分布式消息队列原理
8.5.ZK在kafka的作用,分布式环境中Leader机制和算法研读















