使用神经网络为图像生成标题
我们都知道,神经网络可以在执行某些任务时复制人脑的功能。神经网络在计算机视觉和自然语言生成方面的应用已经非常引人注目。
本文将介绍神经网络的一个这样的应用,并让读者了解如何使用CNNs和RNNs (LSTM)的混合网络实际为图像生成标题(描述)。我们在这个任务中使用的数据集是流行的flickr 8k图像数据集,它是这个任务的基准数据
注意:我们将把数据集分割为7k用于训练,1k用于测试。
我们将首先讨论在我们的混合神经网络中不同的组件(层)和它们的功能。与此同时,我们还将研究使用Tensorflow、Keras和Python开发混合神经网络的实际实现。
神经网络的总体结构
让我们来看看我们将用于生成字幕的神经网络的总体架构。

简单地说,上述神经网络有3个主要组成部分(子网络),每个子网络都有一个特定的任务,即卷积网络(用于从图像中提取特征)、rstm(用于生成文本)和解码器(用于合并两种网络)。
现在让我们详细讨论每个组件并了解它们的工作原理。
图像特征提取器
为了从图像中生成特征,我们将使用卷积神经网络,只需稍加修改。让我们来看看一个用于图像识别的卷积神经网络。

一般的CNN分类模型有两个子网络
Feature Learning Network—负责从图像中生成Feature map的网络(多卷积和池化层的网络)。
分类网络——负责图像分类的全连通深度神经网络(多稠密层、单输出层网络)。
由于我们只对从图像中提取特征感兴趣,而对其分类不感兴趣,所以我们只对CNN的Feature Learning部分进行处理,这就是我们从图像中提取特征的方法。
下面的代码可以用来从任何一组图像提取特征:
import tensorflow as tf
from keras.preprocessing import image
import numpy as np
# function to extract features from image
def extract_image_features():
model = tf.keras.models.Sequential()
# adding first layers of convolution and pooling layers to network
model.add(tf.keras.layers.Conv2D(filters=64, kernel_size=(3,3), input_shape=(90,90,3), padding="VALID", activation="relu"))
model.add(tf.keras.layers.Conv2D(filters=64, kernel_size=(3,3), activation="relu"))
model.add(tf.keras.layers.MaxPool2D(pool_size=2, strides=2))
# adding second layers of convolution and pooling layers to network
model.add(tf.keras.layers.Conv2D(filters=32, kernel_size=(3,3), padding="VALID", activation="relu"))
model.add(tf.keras.layers.Conv2D(filters=32, kernel_size=(3,3), activation="relu"))
model.add(tf.keras.layers.AveragePooling2D(pool_size=2, strides=1))
# flattening the output using flatten layer, since the input to neural net has to be flat
model.add(tf.keras.layers.Flatten())
# model summary
model.summary()
return model
for file in os.listdir(image_path):
path = image_path + "//" + file
img = image.load_img(path, target_size=(90, 90))
img_data = image.img_to_array(img)
img_data = np.expand_dims(img_data, axis=0)
img_data = preprocess_input(img_data)
feature = extract_image_features.predict(img_data)
feature = np.reshape(feature, feature.shape[1])任何人都可以使用上述代码构建自己的图像特征提取器,但有一个问题…
上面的模型太过简单,无法从我们的一组图像中提取出每一个重要的细节,因此会影响整个模型的性能。此外,由于高性能gpu和系统的不可用性,使得模型过于复杂(具有大量神经元的多层密集层)也具有挑战性。
为了解决这个问题,我们在Tensorflow中有非常流行的预训练CNN模型(VGG-16, ResNet50等,由不同大学和组织的科学家开发),可以用于从图像中提取特征。记住,在使用输出层进行特征提取之前,要将它从模型中移除。
下面的代码将让您了解如何使用Tensorflow中这些预先训练好的模型从图像中提取特征。
import tensorflow as tf
from keras.preprocessing import image
from keras.Applications.resnet50 import ResNet50
from keras.applications.resnet50 import preprocess_input
from keras.models import Model
# load the ResNet50 Model
feature_extractor = ResNet50(weights='imagenet', include_top=False)
feature_extractor_new = Model(feature_extractor.input, feature_extractor.layers[-2].output)
feature_extractor_new.summary()
for file in os.listdir(image_path):
path = image_path + "//" + file
img = image.load_img(path, target_size=(90, 90))
img_data = image.img_to_array(img)
img_data = np.expand_dims(img_data, axis=0)
img_data = preprocess_input(img_data)
feature = feature_extractor_new.predict(img_data)
feature_reshaped = np.array(feature).flatten()正如您在下面看到的,如果执行上面的代码,您将看到我们的图像特性只是一个形状-(18432,)的numpy数组。
image_feature_dictionary[list(image_feature_dictionary. Keys())[0]].shape
(18432,)接下来,我们将开发用于为图像生成标题的LSTM网络(RNN)。
用于生成标题的LSTM
文本生成是LSTM网络中最流行的应用之一。LSTM单元格(LSTM网络的基本构建块)能够根据前一层的输出生成输出,即它保留前一层(内存)的输出,并使用该内存生成(预测)序列中的下一个输出。
对于我们的数据集,我们为每张图片设置了5个标题,即总共40k个标题。
让我们看看我们的数据集-

1. A child in a pink dress is climbing up a set of stairs in an entry way.
1. A girl going into a wooden building.
1. A little girl climbing into a wooden playhouse.
1. A little girl climbing the stairs to her playhouse.
1. A little girl in a pink dress going into a wooden cabin.
正如所见,所有的字幕都很好地描述了图片。我们现在的任务是设计一个RNN,它可以为任何相似的图像集复制这个任务。
回到最初的任务,我们首先必须看看LSTM网络是如何生成文本的。对于LSTM来说,网络标题只不过是一长串单独的单词(编码为数字)放在一起。利用这些信息,它试图根据前面的单词预测序列中的下一个单词(记忆)。
在我们的例子中,由于标题可以是可变长度的,所以我们首先需要指定每个标题的开始和结束。我们看看-是什么意思

首先,我们将把和添加到数据集中的每个标题中。在创建最终词汇表之前,我们将对训练数据集中的每个标题进行标记。为了训练我们的模型,我们将从词汇表中删除频率小于或等于10的单词。增加这一步是为了提高我们的模型的一般性能,并防止它过拟合训练数据集。
代码如下:
# loading captions from captions file
import pandas as pd
# loading captions.txt
captions = pd.read_csv('/kaggle/input/flickr8k/captions.txt', sep=",")
captions = captions.rename(columns=lambda x: x.strip().lower())
captions['image'] = captions['image'].apply(lambda x: x.split(".")[0])
captions = captions[['image', 'caption']]
# adding <start> and <end> to every caption
captions['caption'] = "<start> " + captions['caption'] + " <end>"
# in case we have any missing caption/blank caption drop it
print(captions.shape)
captions = captions.dropna()
print(captions.shape)
# training and testing image captions split
train_image_captions = {}
test_image_captions = {}
# list for storing every caption
all_captions = []
# storing training data
for image in train_data_images:
tempDf = captions[captions['image'] == image]
list_of_captions = tempDf['caption'].tolist()
train_image_captions[image] = list_of_captions
all_captions.append(list_of_captions)
# store testing data
for image in test_data_images:
tempDf = captions[captions['image'] == image]
list_of_captions = tempDf['caption'].tolist()
test_image_captions[image] = list_of_captions
all_captions.append(list_of_captions)
print("Data Statistics")
print(f"Training Images Captions {len(train_image_captions.keys())}")
print(f"Testing Images Captions {len(test_image_captions.keys())}")上面的代码将生成下面的输出
train_image_captions[list(train_image_captions. Keys())[150]]
['<start> A brown dog chases a tattered ball around the yard . <end>',
'<start> A brown dog is chasing a tattered soccer ball across a low cut field . <end>',
'<start> Large brown dog playing with a white soccer ball in the grass . <end>',
'<start> Tan dog chasing a ball . <end>',
'<start> The tan dog is chasing a ball . <end>']一旦我们加载了标题,我们将首先使用spacy和Tokenizer(来自tensorflow.preprocessing.)对所有内容进行标记。文本类)。
令牌化就是将一个句子分解成不同的单词,同时删除特殊字符,所有内容都小写。结果是我们在句子中有了一个有意义的单词(记号)的语料库,我们可以在将其用作模型的输入之前对其进行进一步编码。
import spacy
nlp = spacy.load('en', disable=['tagger', 'parser', 'ner'])
# tokenize evry captions, remove punctuations, lowercase everything
for key, value in train_image_captions.items():
ls = []
for v in value:
doc = nlp(v)
new_v = " "
for token in doc:
if not token.is_punct:
if token.text not in [" ", "n", "nn"]:
new_v = new_v + " " + token.text.lower()
new_v = new_v.strip()
ls.append(new_v)
train_image_captions[key] = ls
# create a vocabulary of all the unique words present in captions
# flatten the list
all_captions = [caption for list_of_captions in all_captions for caption in list_of_captions]
# use spacy to convert to lowercase and reject any special characters
tokens = []
for captions in all_captions:
doc = nlp(captions)
for token in doc:
if not token.is_punct:
if token.text not in [" ", "n", "nn"]:
tokens.append(token.text.lower())
# get tokens with frequency less than 10
import collections
word_count_dict = collections.Counter(tokens)
reject_words = []
for key, value in word_count_dict.items():
if value < 10:
reject_words.append(key)
reject_words.append("<")
reject_words.append(">")
# remove tokens that are in reject words
tokens = [x for x in tokens if x not in reject_words]
# convert the token to equivalent index using Tokenizer class of Keras
from keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer()
tokenizer.fit_on_texts(tokens)上面的代码将生成一个字典,其中每个令牌都被编码为整数,反之亦然。示例输出如下所示
tokenizer.word_index {'a': 1,
'end': 2,
'start': 3,
'in': 4,
'the': 5,
'on': 6,
'is': 7,
'and': 8,
'dog': 9,
'with': 10,
'man': 11,
'of': 12,
'two': 13,
'black': 14,
'white': 15,
'boy': 16,
'woman': 17,
'girl': 18,
'wearing': 19,
'are': 20,
'brown': 21.....}在此之后,我们需要找到词汇表的长度和最长标题的长度。让我们看看这两种方法在创建模型时的重要性。
词汇长度:词汇长度基本上是我们语料库中唯一单词的数量。此外,输出层中的神经元将等于词汇表长度+ 1(+ 1表示由于填充序列而产生的额外空白),因为在每次迭代时,我们需要模型从语料库中生成一个新单词。
最大标题长度:因为在我们的数据集中,即使对于相同的图像,标题也是可变长度的。让我们试着更详细地理解这个

正如您所看到的,每个标题都有不同的长度,因此我们不能将它们用作我们的LSTM模型的输入。为了解决这个问题,我们填充填充每个标题到最大标题的长度。

注意,每个序列都有一组额外的0来增加它的长度到最大序列。
# compute length of vocabulary and maximum length of a caption (for padding)
vocab_len = len(tokenizer.word_counts) + 1
print(f"Vocabulary length - {vocab_len}")
max_caption_len = max([len(x.split(" ")) for x in all_captions])
print(f"Maximum length of caption - {max_caption_len}")和输出的模型创建训练数据集。对于我们的问题,我们有两个输入和一个输出。为了便于理解,让我们更详细地看看这个

对于每个图像我们都有
图像特征(X1):利用ResNet50模型提取的形状的Numpy数组(18432,)
输入序列(X2):这需要更多的解释。每个标题只是一个序列列表,我们的模型试图预测序列中下一个最好的元素。因此,对于每个标题,我们将首先从序列中的第一个元素开始,对该元素的相应输出将是下一个元素。在下一次迭代中,前一次迭代的输出将和前一次迭代的输入(内存)一起成为新的输入,这样一直进行,直到我们到达序列的末尾。
输出(y):序列中的下一个单词。
下面的代码可以用来实现上面创建训练数据集的逻辑-
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
# generator function to generate inputs for model
def create_trianing_data(captions, images, tokenizer, max_caption_length, vocab_len, photos_per_batch):
X1, X2, y = list(), list(), list()
n=0
# loop through every image
while 1:
for key, cap in captions.items():
n+=1
# retrieve the photo feature
image = images[key]
for c in cap:
# encode the sequence
sequnece = [tokenizer.word_index[word] for word in c.split(' ') if word in list(tokenizer.word_index.keys())]
# split one sequence into multiple X, y pairs
for i in range(1, len(sequence)):
# creating input, output
inp, out = sequence[:i], sequence[i]
# padding input
input_seq = pad_sequences([inp], maxlen=max_caption_length)[0]
# encode output sequence
output_seq = to_categorical([out], num_classes=vocab_len)[0]
# store
X1.append(image)
X2.append(input_seq)
y.append(output_seq)
# yield the batch data
if n==photos_per_batch:
yield ([np.array(X1), np.array(X2)], np.array(y))
X1, X2, y = list(), list(), list()
n=0合并两个子网络
现在我们已经开发了两个子网络(用于生成字幕的图像特征提取器和LSTM),让我们结合这两个网络来创建我们的最终模型。
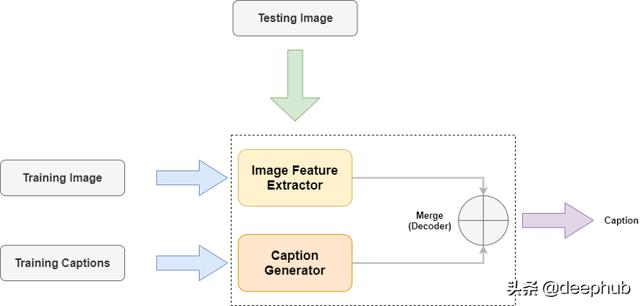
对于任何一幅新图像(必须与训练中使用的图像相似),我们的模型将根据它在训练相似的图像和字幕集时获得的知识生成标题。
下面的代码创建了最终的模型
import keras
def create_model(max_caption_length, vocab_length):
# sub network for handling the image feature part
input_layer1 = keras.Input(shape=(18432))
feature1 = keras.layers.Dropout(0.2)(input_layer1)
feature2 = keras.layers.Dense(max_caption_length*4, activation='relu')(feature1)
feature3 = keras.layers.Dense(max_caption_length*4, activation='relu')(feature2)
feature4 = keras.layers.Dense(max_caption_length*4, activation='relu')(feature3)
feature5 = keras.layers.Dense(max_caption_length*4, activation='relu')(feature4)
# sub network for handling the text generation part
input_layer2 = keras.Input(shape=(max_caption_length,))
cap_layer1 = keras.layers.Embedding(vocab_length, 300, input_length=max_caption_length)(input_layer2)
cap_layer2 = keras.layers.Dropout(0.2)(cap_layer1)
cap_layer3 = keras.layers.LSTM(max_caption_length*4, activation='relu', return_sequences=True)(cap_layer2)
cap_layer4 = keras.layers.LSTM(max_caption_length*4, activation='relu', return_sequences=True)(cap_layer3)
cap_layer5 = keras.layers.LSTM(max_caption_length*4, activation='relu', return_sequences=True)(cap_layer4)
cap_layer6 = keras.layers.LSTM(max_caption_length*4, activation='relu')(cap_layer5)
# merging the two sub network
decoder1 = keras.layers.merge.add([feature5, cap_layer6])
decoder2 = keras.layers.Dense(256, activation='relu')(decoder1)
decoder3 = keras.layers.Dense(256, activation='relu')(decoder2)
# output is the next word in sequence
output_layer = keras.layers.Dense(vocab_length, activation='softmax')(decoder3)
model = keras.models.Model(inputs=[input_layer1, input_layer2], outputs=output_layer)
model.summary()
return model在编译模型之前,我们需要给嵌入层添加权重。这是通过为语料库(词汇表)中出现的每个标记创建单词嵌入(在高维向量空间中表示标记)来实现的。有一些非常流行的字嵌入模型可以用于这个目的(GloVe, Gensim嵌入模型等)。
我们将使用Spacy内建的"encoreweb_lg"模型来创建令牌的向量表示(即每个令牌将被表示为(300,)numpy数组)。
下面的代码可以用于创建单词嵌入,并将其添加到我们的模型嵌入层。
# create word embeddings
import spacy
nlp = spacy.load('en_core_web_lg')
# create word embeddings
embedding_dimension = 300
embedding_matrix = np.zeros((vocab_len, embedding_dimension))
# travel through every word in vocabulary and get its corresponding vector
for word, index in tokenizer.word_index.items():
doc = nlp(word)
embedding_vector = np.array(doc.vector)
embedding_matrix[index] = embedding_vector
# adding embeddings to model
predictive_model.layers[2]
predictive_model.layers[2].set_weights([embedding_matrix])
predictive_model.layers[2].trainable = False现在我们已经创建了所有的东西,我们只需要编译和训练我们的模型。
注意:由于我们任务的复杂性,这个网络的训练时间会非常长(具有大量的epoch)
# get training data
train_data = create_trianing_data(train_image_captions, train_image_features, tokenizer, max_caption_len, vocab_length, 32)
# initialize model
model = create_model(max_caption_len, vocab_len)
steps_per_epochs = len(train_image_captions)//32
# compile model
model.compile(optimizer='adam', loss='categorical_crossentropy')
model.fit_generator(train_data, epochs=100, steps_per_epoch=steps_per_epochs)为了生成新的标题,我们首先需要将一幅图像转换为与训练数据集(18432)图像相同维数的numpy数组,并使用作为模型的输入。
在序列生成过程中,一旦在输出中遇到,我们就会终止这个过程。
import matplotlib.pyplot as plt
import seaborn as sns
from PIL import Image
%matplotlib inline
# method for generating captions
def generate_captions(model, image, tokenizer.word_index, max_caption_length, tokenizer.index_word):
# input is <start>
input_text = '<start>'
# keep generating words till we have encountered <end>
for i in range(max_caption_length):
seq = [tokenizer.word_index[w] for w in in_text.split() if w in list(tokenizer.word_index.keys())]
seq = pad_sequences([sequence], maxlen=max_caption_length)
prediction = model.predict([photo,sequence], verbose=0)
prediction = np.argmax(prediction)
word = tokenizer.index_word[prediction]
input_text += ' ' + word
if word == '<end>':
break
# remove <start> and <end> from output and return string
output = in_text.split()
output = output[1:-1]
output = ' '.join(output)
return output
# traverse through testing images to generate captions
count = 0
for key, value in test_image_features.items():
test_image = test_image_features[key]
test_image = np.expand_dims(test_image, axis=0)
final_caption = generate_captions(predictive_model, test_image, tokenizer.word_index, max_caption_len, tokenizer.index_word)
plt.figure(figsize=(7,7))
image = Image.open(image_path + "//" + key + ".jpg")
plt.imshow(image)
plt.title(final_caption)
count = count + 1
if count == 3:
break现在让我们检查模型的输出





总结
正如你所看到的,我们的模型为一些图片生成了足够好的标题,但有些标题并没有说明。
这可以通过增加epoch、训练数据、向我们的最终模型添加层来改善,但所有这些都需要高端机器(gpu)进行处理。
这就是我们如何用我们自己的深度学习模型为图片生成标题。
作者:Akash Chauhan
deephub翻译组
















